800 B
800 B
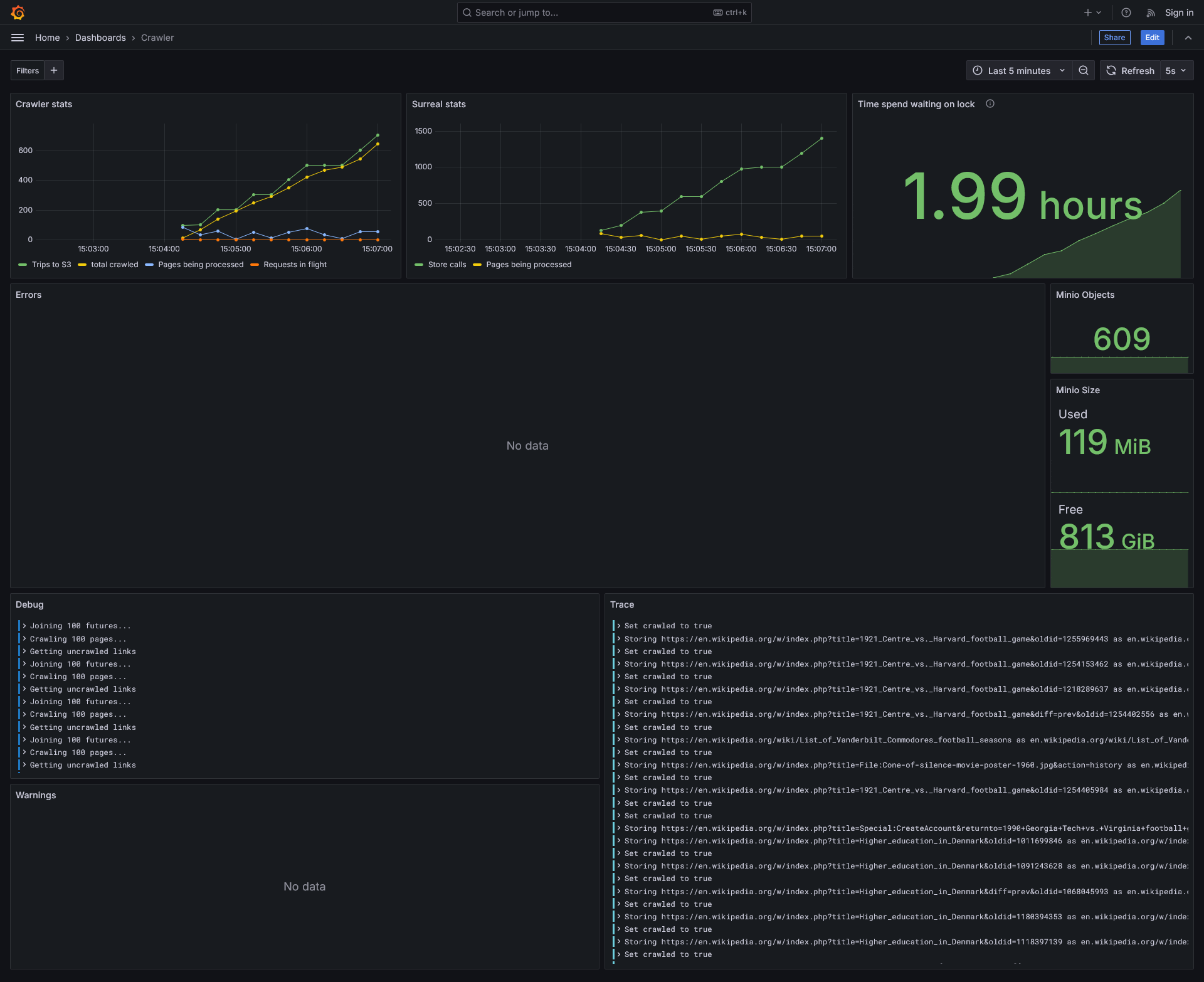
Surreal Crawler
Crawls sites saving all the found links to a surrealdb database. It then proceeds to take batches of 100 uncrawled links untill the crawl budget is reached. It saves the data of each site in a minio database.
TODO
- Domain filtering - prevent the crawler from going on alternate versions of wikipedia.
- Conditionally save content - based on filename or file contents
- GUI / TUI ? - Graphana
- Better asynchronous getting of the sites. Currently it all happens serially.
- Allow for storing asynchronously
3/17/25: Took >1hr to crawl 100 pages
3/19/25: Took 20min to crawl 1000 pages This ment we stored 1000 pages, 142,997 urls, and 1,425,798 links between the two.
3/20/25: Took 5min to crawl 1000 pages
About